安装了的Office2010之后,不少人发现“Microsoft Office工具”里找不到OCR(Optical Character Recognition的缩写,意思是光学字符识别,也可简单地称为文字识别,是文字自动输入的一种方法)的工具。是不是出了什么错呢?其实不是的,只是Office2010的OCR工具隐藏在Onenote里面罢了。所以使用OCR功能得先安装OneNote。
我们来认识一下这个功能:
首先来试验一下对于电脑屏幕抓图中的文本的识别效果,这在需要复制屏幕中不可选的文字时很有用。
我们使用“插入 - 屏幕剪辑”功能来抓图。
抓到的截图如下:

右键点击图片,通过“复制图片中的文本”功能来识别内容:

然后粘贴到旁边,所得到的内容如下:
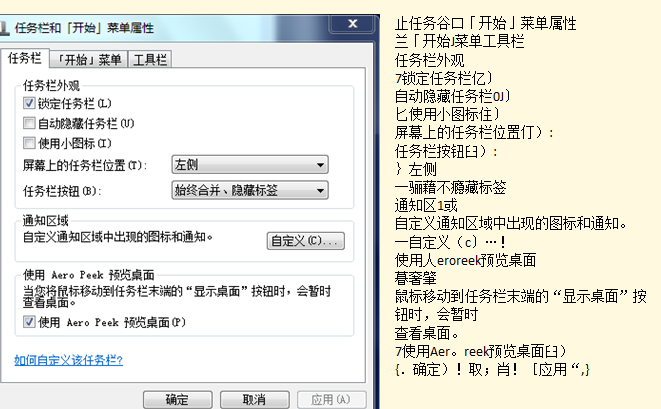
因为此界面中有很多视觉元素干扰,所以识别结果并不好,但是界面上的文字基本上都被正确识别出来了,如果换成纯文本区域的抓图的话,效果将会很好。
接下来,针对扫描件的文本识别进行测试,此功能可以减轻我们对纸质内容的转换和录入操作。
这里只需要将扫描图插入文档中即可,为了便于展示,此处中仅使用扫描件的一小部分用做测试:

同上面一样,通过“复制图片中的文本”功能进行识别,识别后的内容和原图对比如下:

这里的识别效果非常优秀,令人叹服。
当Adobe PDF 文件中内容是图片时,若想转化为Word文档,就要用到这个批量转化的功能了。
首先打开Adobe PDF 文件:
点击左边的“打印”按钮

出现下面的界面

点“确定”后,转至OneNote

选择一个位置后,确定

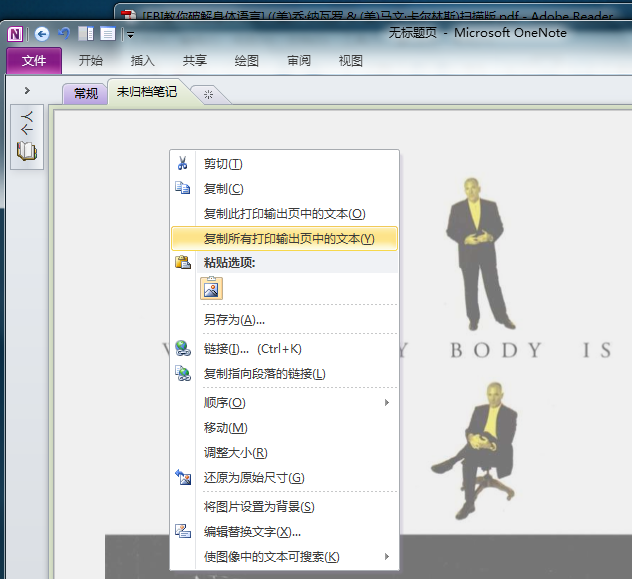
同前,右击图片,选择“复制所有打印输出页中的文本(Y)”
待处理完后粘贴到Word中即可。整体对比效果如图:
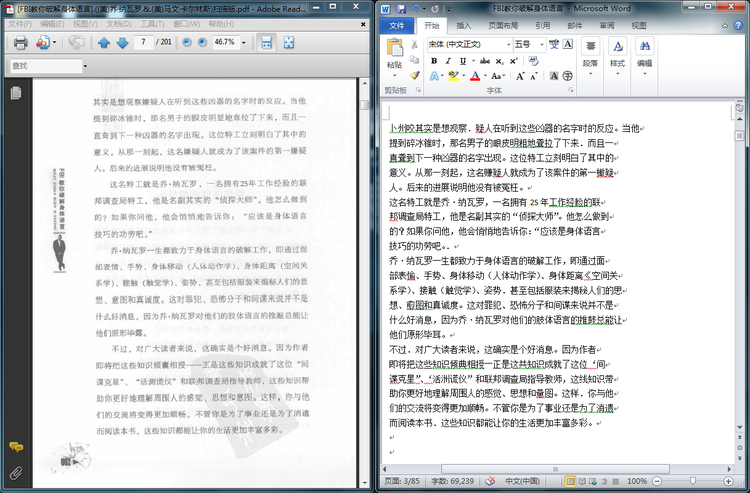
实际效果对比如下:

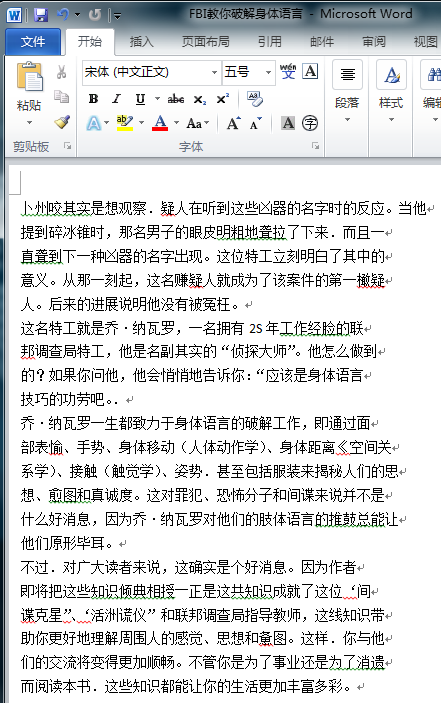
此功能也是很有用处的,比如文档中收录了一些名片的扫描或拍摄件,希望通过搜索迅速找到某人时。
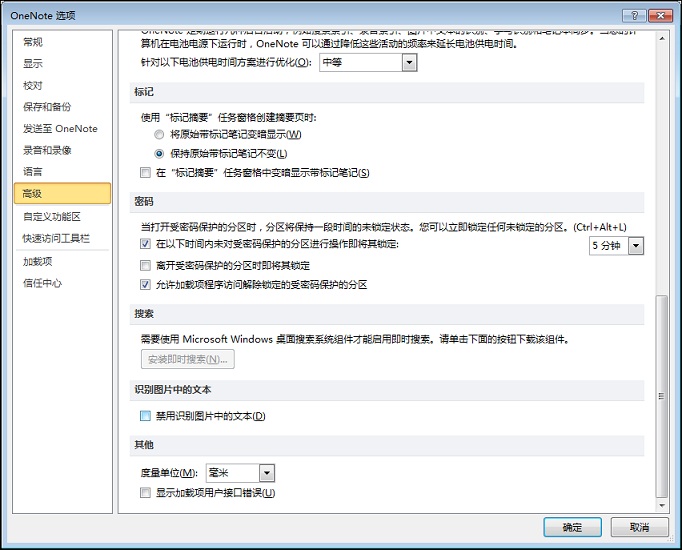
开启这一功能,需要在设置中取消“禁用识别图片中的文本”选项:
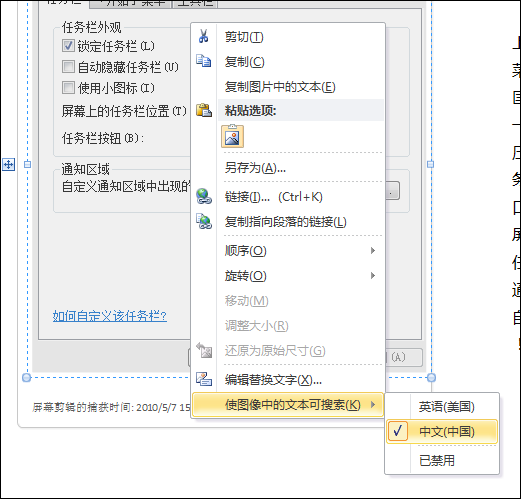
然后,可以通过快捷菜单设定图片中的主体语言:
这样图片就可以被搜索了,试一下: